
當你懷疑硬盤有問題,甚至是NAS主動給你Bee Bee報錯時候,你一定就會碰到硬盤的健康表:S.M.A.R.T. 。小U發現網上少有系統總結S.M.A.R.T.的資料,所以結合自己的最近遇到的硬碟問題整理出本文,希望幫到你即時拯救生病的硬碟和裡面的寶貴數據。
摘要節點

S.M.A.R.T.是什麼?
S.M.A.R.T. (Self-Monitoring, Analysis, and Reporting Technology) 是一種監控硬盘驅動器(HDD)和固态硬盘驅動器(SSD)健康狀況的技術。它可以提前警告用戶潛在的磁盤硬件問題,從而減少數據丟失的風險。
S.M.A.R.T.技術會監控和分析多個與磁盤健康有關的指標,包括讀寫錯誤率、硬盘驅動器溫度、使用時間等等。並非所有的硬盘都配備了S.M.A.R.T.功能,但是大多數現代硬盘(製造日期在2000年以後的)通常都支持這一功能。你可以使用各種工具來檢查和解讀S.M.A.R.T.數據,這些工具通常可以提供你需要的所有信息來判斷硬盘的健康狀況。
有哪些工具可以讀取HDD/SSD的S.M.A.R.T.數據
所有主流操作系統都支援讀取S.M.A.R.T.數據,如在Windows上,你可以使用“CrystalDiskInfo”或“Hard Disk Sentinel”等工具來檢查S.M.A.R.T.狀態。在Linux中,你可以使用smartctl命令行工具來檢查和解讀S.M.A.R.T.數據。在NAS的操作界面中也可讀取S.M.A.R.T.數據。
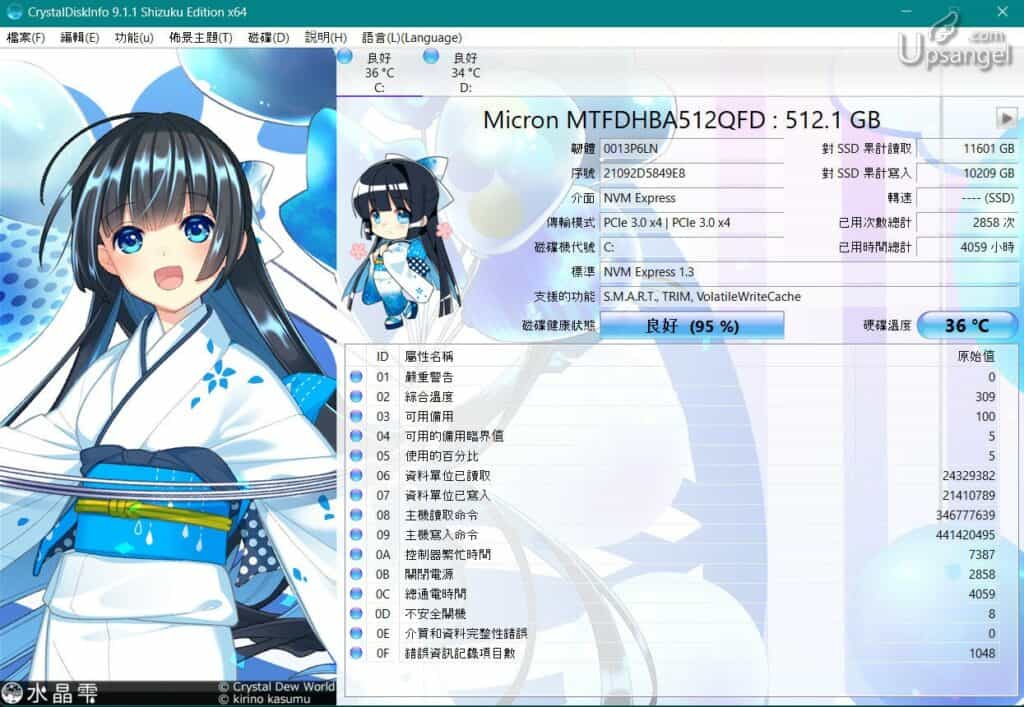
如何解讀S.M.A.R.T.數據
哪幾個S.M.A.R.T.數據項目是最關乎HDD/SDD健康度的?
S.M.A.R.T.有好多項目,其中最能反映磁盤健康狀態的指標有下列幾個:
- Reallocated Sector Count 重定位磁區數量 – 這是一個關鍵的指標,因為它顯示了已經被發現為有缺陷並且被重新分配的扇區數量。這個數值的高值或快速增加可能指示硬碟驅動器正在失效。
- Current Pending Sector Count 等候重定位磁區數量 – 這個屬性指示著等待重新映射的不穩定扇區的數量。增長的掛起扇區數量可以是硬碟退化的徵兆。
- Seek Error Rate 尋道錯誤率 – 這更適用於HDD,表示找不到正確軌道的失敗率。高數值可能表明一個機械問題。
- Read Error Rate 讀取錯誤率 – 表示在從磁碟讀取資料時發生的硬體錯誤率。高數值可能表明磁碟有問題。
- Uncorrectable Sector Count 無法糾正的磁區數量 – 這指的是讀取/寫入一個扇區時的不可糾正錯誤的數量。高數值是硬碟驅動器可能故障的嚴重警告。
- Spin Retry Count: 磁頭旋轉重試計數(特定於HDD)- 指示旋轉HDD的失敗嘗試次數。增加的值可能表明一個動力或機械問題。
如何解讀S.M.A.R.T.數據中的Current、Normalized, Worst 和Threshold?
S.M.A.R.T. 系統不僅用來監視硬碟的多種參數,它還提供了一套框架來解讀這些參數的值。在S.M.A.R.T. 資料中有幾個重要的欄位,包括“Current”(當前)、“Worst”(最差)、“Threshold”(閾值)、和“Normalized”(標準化)。下面我們來分別解析這些術語和它們的意義:
“Current”(當前):
- 意義:表示該參數的即時值。
- 如何解讀:它通常反映出硬碟目前的健康狀況,這是一個動態的數值,會隨著硬碟的使用情況而變化。
“Worst”(最差):
- 意義:這表示硬碟在其使用歷史上該參數的最差記錄。
- 如何解讀:它可以幫你理解硬碟在歷史時期的最差狀態。如果這個數值非常靠近閾值,你應該更加注意這個參數。
“Normalized”(標準化):
- 意義:這是一個將“當前”值通過特定算法轉換成範圍在0-100或0-200的標準化值。
- 如何解讀:較高的標準化值通常代表硬碟的健康狀態較好,而較低的則可能意味著存在問題。這個數值能協助你更好地理解硬碟的整體健康狀態。
“Threshold”(閾值):
- 意義:這是由硬碟製造商設定的參數下限,如果“標準化”值低於這個閾值,硬碟會通常被標記為“失敗”。
- 如何解讀:如果某個參數的“標準化”值低於或接近它的“閾值”,通常是一個警告信號,表示硬碟可能即將出現問題。
在解讀S.M.A.R.T. 值時,不僅要注意目前的參數值,也要考慮它們與閾值的關系以及它們隨時間的變化趨勢。如果有任何S.M.A.R.T. 值顯示潛在的問題,建議你及時備份所有重要的資料,以避免資料丟失。
壞碟/將會壞碟的S.M.A.R.T.實例分析
例子1. Windows CrystalDiskInfo分析
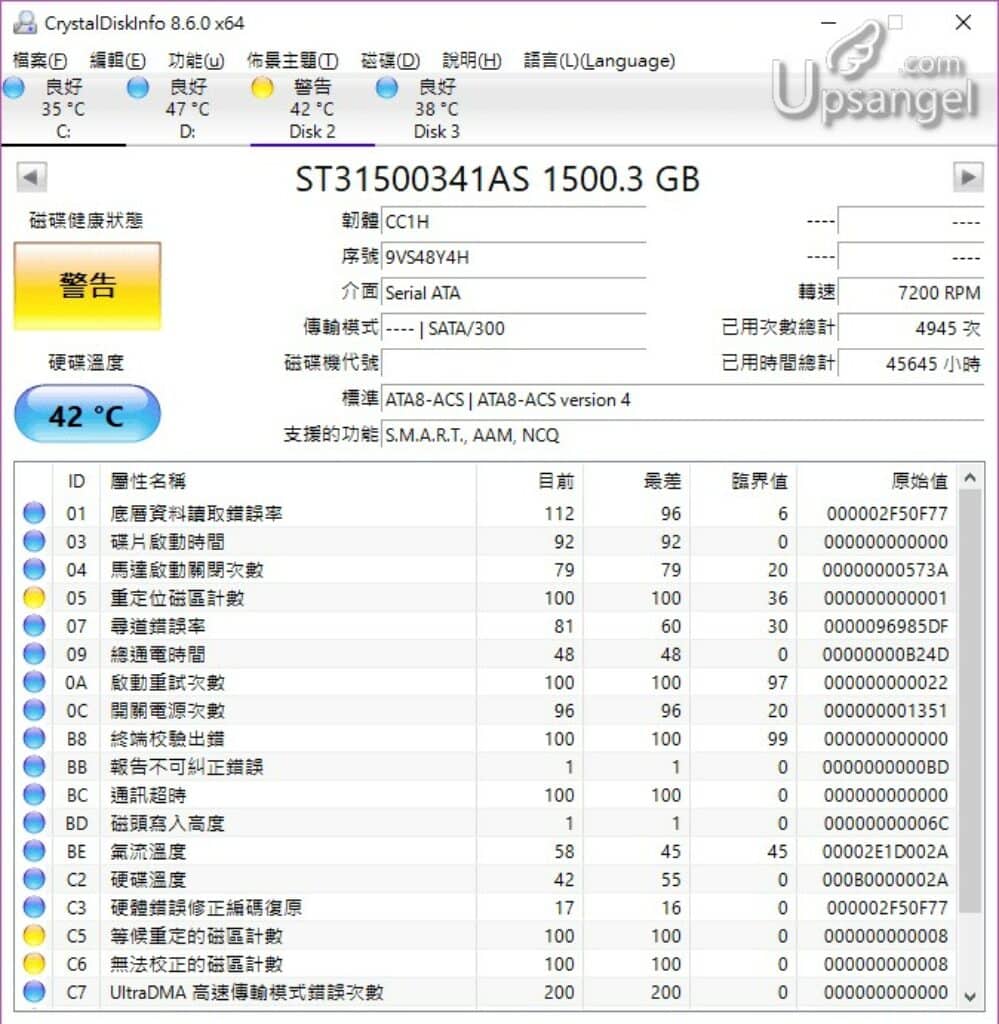
從CrystalDiskInfo讀取的SMART value可見,這塊Seagate的硬碟已經出現明顯問題,重定位磁區數的原始值RAW VALUE是1,等候重定位和無法矯正的磁區計數的原始值RAW VALUE是8,證明數據已經開始出現問題。
例子2. Linux / PVE上的SMART例子
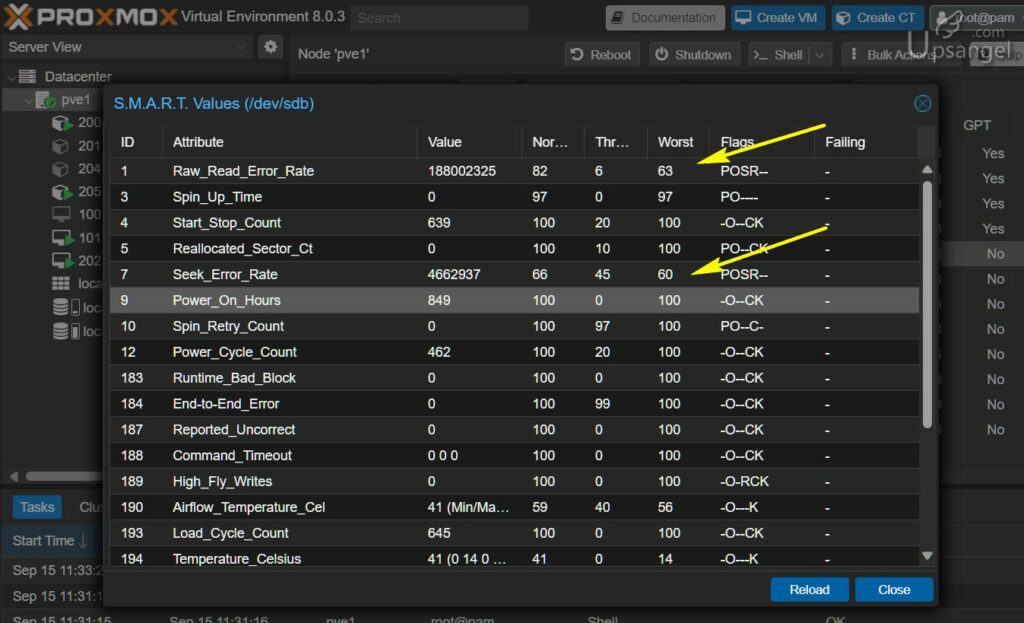
這是小U自用的一塊1TB Seagate機械盤,他的讀取和尋道錯誤率很高,讀取最差剩63,尋道剩60。但是這個盤沒有任何Reallocated的磁區,證明這個盤的問題應該是讀取磁頭和機械臂出現問題,磁碟磁粉應該還好。
爲什麼S.M.A.R.T.正常但是DSM NAS顯示磁盤已損壞?
小U早幾個月就遇到過這個情況,SYNOLOGY 的NAS不斷咇咇響,顯示一個磁盤已經損壞:
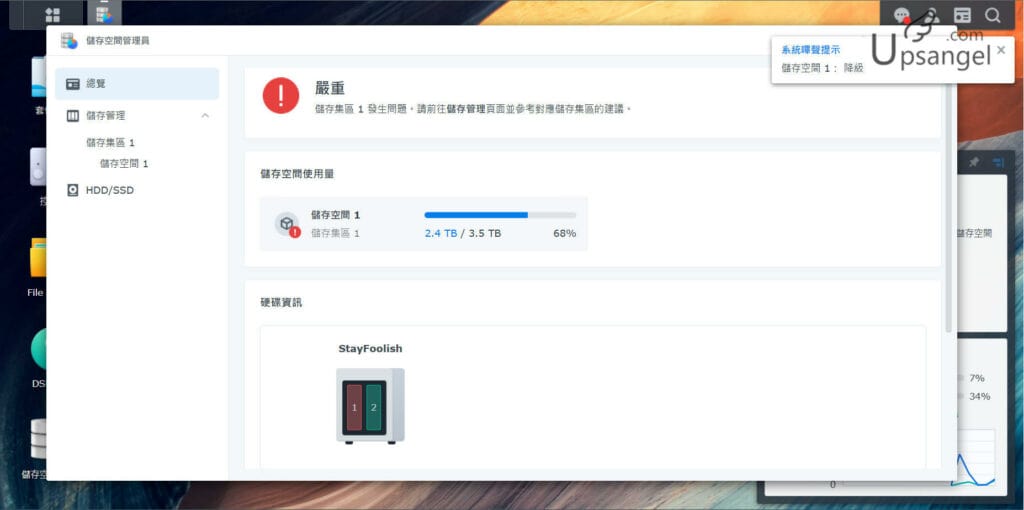
但是查看他的SMART卻顯示”健康“,到底爲什麼會這樣,哪個判斷才是正確呢?
SMART不是判斷硬盤健康的唯一方法
經過研究後,小U發現S.M.A.R.T.像是教練監測一個運動員的表現,跑得快不快,動作表不標準。但是運動員有沒有癌症S.M.A.R.T.看不到。對於磁盤健康來說,資料的完整度是最重要的。使用數據校驗技術(checksum)是比對資料是否完好、有沒有損壞的。如果有損壞就認爲是有”癌症“初期了(因爲磁盤一旦出現數據丟失,情況只會越來越嚴重)。
爲了準確判定有沒有”病“(資料損壞),最好要採用有數據校驗功能的文件系統,例如BTRFS,ZFS等,詳細請參考小U前文:
Upsangel.com
正因爲小U的DSM是採用了BTRFS文件系統組建的SHR陣列,所以具有數據校驗功能。數據校驗發現磁盤已經開始丟失數據,就果斷判定磁盤已經生病,無論SMART value是怎麼樣。
哪些NAS / 文件系統具有數據校驗或相似功能?
既然S.M.A.R.T.只能反映HDD的物理健康度,那麼文件的完好健康度要有什麼系統才能提供校驗功能呢?小U粗略列舉幾個:
- Synology SHR / Unraid on BTRFS
- QNAP / TrueNAS / Unraid / Proxmox on ZFS
- RAID5或RAIDZ5等類似的有3個磁盤提供PARITY校驗功能
- 較弱但好過沒有的校驗:XFS、NTFS、APFS (Apple File System)
爲什麼我的SATA3 / NVME M2 SSD的S.M.A.R.T.完全不一樣?
S.M.A.R.T.是在20年前定義的標準,雖然隨着SSD流行,S.M.A.R.T.也有UPDATE,但是SSD的S.M.A.R.T.已經和HDD機械硬盤很不一樣,很多值都沒有給出Threshold臨界值,導致S.M.A.R.T.的參考價值很“主觀”。到了NVME時代S.M.A.R.T.就更不一樣,小U另開文章和大家探討SSD的健康度。



